Key Takeaways: AI Infrastructure and Operations Fundamental by NVIDIA.
The underlying AI infrastructure that drives the success of today’s AI development by NVIDIA.
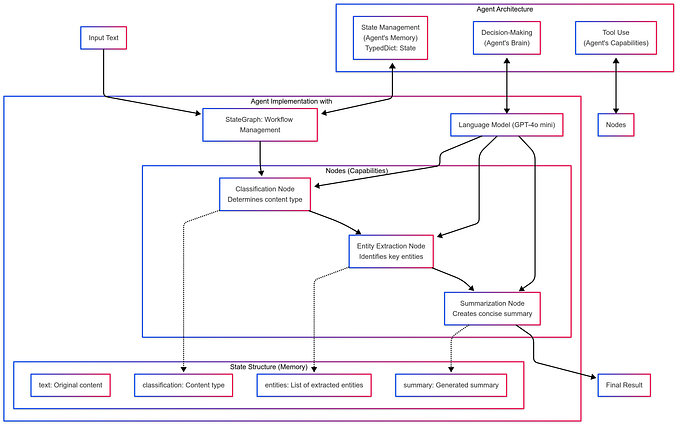
AI Infrastructure and Operations: Overview
Beyond AI development, understanding the infrastructure that powers advanced model training and deployment is essential. One of the key factors enabling the practical application of complex theoretical mathematics is the availability of high-performance computing resources.
I completed the “AI Infrastructure and Operations Fundamentals” course by NVIDIA on Coursera to deepen my understanding of AI infrastructure. This course explores how industries design and build infrastructure to deploy AI models at scale and process millions of real-time inputs. I summarize key insights from the course with a primary focus on AI infrastructure. However, I highly recommend taking the full 11-hour course for a comprehensive understanding.
Course Structure
The course consists of four modules followed by a final assessment, which is required for obtaining the certification. The modules are included:
- Module 1: Introduction to AI
- Module 2: AI Infrastructure
- Module 3: AI Operations
- Module 4: Course Completion Quiz
This article will focus on Module 2, which covers the essential components of AI infrastructure.
The Three Pillars of a Modern Data Center
The three pillars of a modern data center are essential components that enable the efficient handling of large-scale AI workloads. These pillars are CPU, GPU, and DPU, which work together to optimize performance and support diverse AI workloads in a data center environment.
- CPU (Central Processing Unit): Handles general-purpose application processing and system management.
- GPU (Graphics Processing Unit): Designed for parallel processing and is used for accelerated computing, particularly in AI and deep learning applications.
- DPU (Data Processing Unit): Manages data-intensive functions such as communication processing, compression, and encryption, which offloads these tasks from the CPU to enhance overall efficiency.
What Are GPUs?
GPUs (Graphics Processing Units) are specialized electronic circuits that manipulate and modify memory to accelerate image rendering. This is necessary because images consist of millions of pixels, which represent position, colour, and brightness. GPUs process these pixels at high speed to ensure smooth visuals without perceptible delays or inconsistencies, significantly enhancing performance in graphics-related tasks.
GPU architecture consists of multiple GPU cores enabling parallel processing and onboard cache memory that optimizes data retrieval. Another critical component is high-speed GPU memory, specifically designed for GPUs and often shared across multiple units to accelerate computation.
Key GPU Architecture Features:
- Parallel Processing Cores: Enable simultaneous computation of multiple tasks.
- Onboard Cache Memory: Optimizes data retrieval for high-speed processing.
- High-Speed GPU Memory: Specialized memory architecture designed for data-intensive AI applications.
CPUs vs. GPUs
CPUs (Central Processing Units) are computer components designed to process complex instruction sets that execute, decode, and manipulate data. The key difference between CPUs and GPUs lies in their processing architecture. CPUs are optimized for sequential processing, featuring a few high-performance cores designed to handle complex instructions efficiently. In contrast, GPUs are built for parallel processors, which are equipped with many smaller cores capable of handling multiple tasks simultaneously.
CPUs are better suited for tasks that require high single-threaded performance, such as running an operating system and executing general-purpose applications. Meanwhile, GPUs excel in workloads that benefit from parallelization, such as image processing, deep learning, and large-scale mathematical computations.
Key CPU and GPU Difference:
- CPUs are optimized for sequential processing with fewer and high-performance cores, making them suitable for complex logic execution.
- GPUs excel at parallel processing, comprising thousands of smaller cores optimized for handling multiple computations simultaneously, making them ideal for AI and deep learning workloads.
Data Processing Units (DPUs)
Data Processing Units (DPUs) are specialized processors that enhance the performance and efficiency of data centers, particularly in cloud computing and AI workloads. Their primary function is to offload, accelerate, and isolate infrastructure tasks from the CPU, allowing it to focus on running applications more efficiently.
DPUs leverage hardware acceleration to handle infrastructure functions faster than traditional CPUs. This functionality helps manage network traffic and overall application performance. A notable example is the NVIDIA BlueField-3 DPU that provides high-speed connectivity, offloading capabilities, and network security for AI-driven data centers.
Key DPU Architecture Features:
- Offloading networking, security, and storage functions from CPUs.
- Accelerating AI model performance by reducing computational bottlenecks
- Enhancing security and data processing efficiency
NVIDIA’s GPU and CPU Architectures
NVIDIA has developed several specialized architectures to support AI workloads, including:

Blackwell GPU Architecture
The foundation of next-generation generative AI is designed to handle large-scale AI workflows and accelerate inference and training of large language models (LLMs). The NVIDIA B200 GPU exemplifies this architecture, delivering the power and performance required for transformer-based models. It leverages custom Blackwell Tensor Core technology, NVIDIA TensorRT-LLM, and the NeMo framework to accelerate inference and training for LLMs and mixture-of-experts (MoE) models.

Hopper GPU Architecture
The engine behind the world’s AI infrastructure that accelerates large-scale AI, high-performance computing (HPC), and data analytics, as well as applications like conversational AI and language processing. The NVIDIA B200 GPU is an example of this architecture. It features NVIDIA Confidential Computing to protect sensitive data and AI models from unauthorized access without compromising performance.
Ada Lovelace GPU Architecture
The engine behind AI-based neural graphics is designed to deliver revolutionary performance for gaming, AI-powered graphics, and ray tracing. An example of this architecture is L40s GPU, which offers accelerated AI performance with fourth-generation tensor cores, the specialized hardware units found in NVIDIA GPUs.

Grace CPU Architecture
The breakdown of CPUs for modern data centers focuses on high-performance computing and large-scale data processing. The NVIDIA Grace CPU is NVIDIA's first CPU built on Arm architecture and specifically designed for high-performance computing applications. It is also well-suited for cloud computing and hyper-scale data centers, which offer exceptional energy efficiency.
AI Data Center Networking
In AI infrastructure, high-bandwidth and low-latency networking are critical components to achieve optimal performance, particularly as AI workloads increasingly demand greater computational power. These network characteristics directly influence GPU utilization, a critical factor as AI models and datasets expand in size and complexity. To meet these demands, AI data centers typically rely on four distinct network types, each tailored to specific functions within the ecosystem:
Compute Network: Engineered to eliminate bottlenecks and maximize throughput, this network ensures that AI workloads, such as training large-scale neural networks, run efficiently across GPU clusters.
Storage Network: Designed for high-throughput connectivity. It provides rapid access to shared storage systems housing expansive AI training datasets to minimize delays in data retrieval.
In-Band Management Network: This network links management nodes to support essential services like Secure Shell (SSH) access and Domain Name System (DNS) resolution, ensuring seamless operational control.
Out-of-Band Management Network: This network offers a lifeline for remote server administration, which enables system recovery and oversight even during hardware or software failures.
These networks together form the backbone of a robust AI data center, enabling the seamless interplay of computation, storage, and management required for cutting-edge AI applications.
InfiniBand Networking for AI
InfiniBand is an exceptional high-performance networking solution purpose-built for AI and high-performance computing (HPC) workloads among the technologies powering AI infrastructure. Several features that make them distinctive are included:
Ultra-High Data Transfer Rates: InfiniBand delivers exceptional bandwidth, making it ideal for handling the massive data flows inherent in large-scale AI model training and inference.
Low Latency: By minimizing transmission delays, it supports real-time AI applications where split-second responsiveness is paramount, such as autonomous systems or live inference pipelines.
Remote Direct Memory Access (RDMA): This capability allows devices to directly access memory on remote systems without involving the host CPU, significantly boosting performance by reducing overhead and latency.
InfiniBand’s ability to combine speed, efficiency, and scalability makes it a cornerstone of modern AI networking, particularly for distributed training environments where GPUs must communicate rapidly and reliably.
AI Storage Considerations
AI workloads generate and process enormous datasets, placing unique demands on storage infrastructure. To keep pace, storage solutions must be fast, scalable, and adaptable to the specific needs of each workload. Several storage architectures are commonly deployed in AI data centers, each with distinct advantages:
Local Storage: Offers low latency and direct access to data, making it suitable for compute-intensive tasks on individual nodes. However, its scalability is constrained by the physical limits of local hardware.
Network File Systems (NFS): Provides centralized storage accessible by multiple compute nodes, streamlining data sharing but potentially introducing bottlenecks under heavy load.
Parallel and Distributed File Systems: Optimized for high-performance, large-scale AI workloads, this storage distributes data across multiple nodes to enable concurrent access and processing.
Object Storage Systems: This storage is designed for scalability and excels in AI data lakes offering cost-effective, flexible storage for vast unstructured datasets.
Choosing the right storage solution hinges on balancing performance, capacity, and cost. NVIDIA enhances this ecosystem by partnering with validated storage providers to ensure seamless integration, optimized performance, and robust security tailored to AI workloads.
NVIDIA AI Cloud Solutions
NVIDIA is at the forefront of AI innovation, offering cloud-based solutions that accelerate AI adoption across enterprise and cloud environments. These offerings are designed to simplify the development, deployment, and scaling of AI initiatives:
NVIDIA AI Enterprise: A comprehensive and cloud-native software platform that streamlines the development, training, and deployment of AI models, providing enterprises with a unified toolkit for AI innovation.
NGC Catalog: A repository of pre-trained models, frameworks, and optimized workflows, enabling developers to jumpstart projects with battle-tested resources tailored for AI and machine learning.
NVIDIA DGX Cloud: A multi-node, enterprise-grade platform for AI training, engineered to handle massive workloads with ease, leveraging NVIDIA’s cutting-edge hardware and software optimizations.
NVIDIA AI Foundations: A service that empowers enterprises to create custom generative AI models, backed by cloud-optimized resources and expertise to accelerate development cycles.
These solutions collectively lower the barriers to entry for AI deployment, delivering scalable and high-performance tools that cater to the diverse needs of modern organizations. By integrating advanced networking, storage, and cloud capabilities, NVIDIA is driving the evolution of AI infrastructure enabling businesses to harness the full potential of artificial intelligence.
Conclusion
Understanding AI infrastructure is essential for deploying scalable and efficient AI systems. This article provided a high-level overview of the key AI hardware components, networking solutions, and storage considerations critical for AI data centers.
I highly recommend taking the full “AI Infrastructure and Operations Fundamentals” course by NVIDIA on Coursera for a deeper dive into AI infrastructure. If you have any questions or need further clarification, feel free to ask!